The only API you need to Crawl the web.
Turn any URL into clean, structured data. Bypass anti-bot defenses, render JavaScript, and get LLM-ready output — all with a single API call.
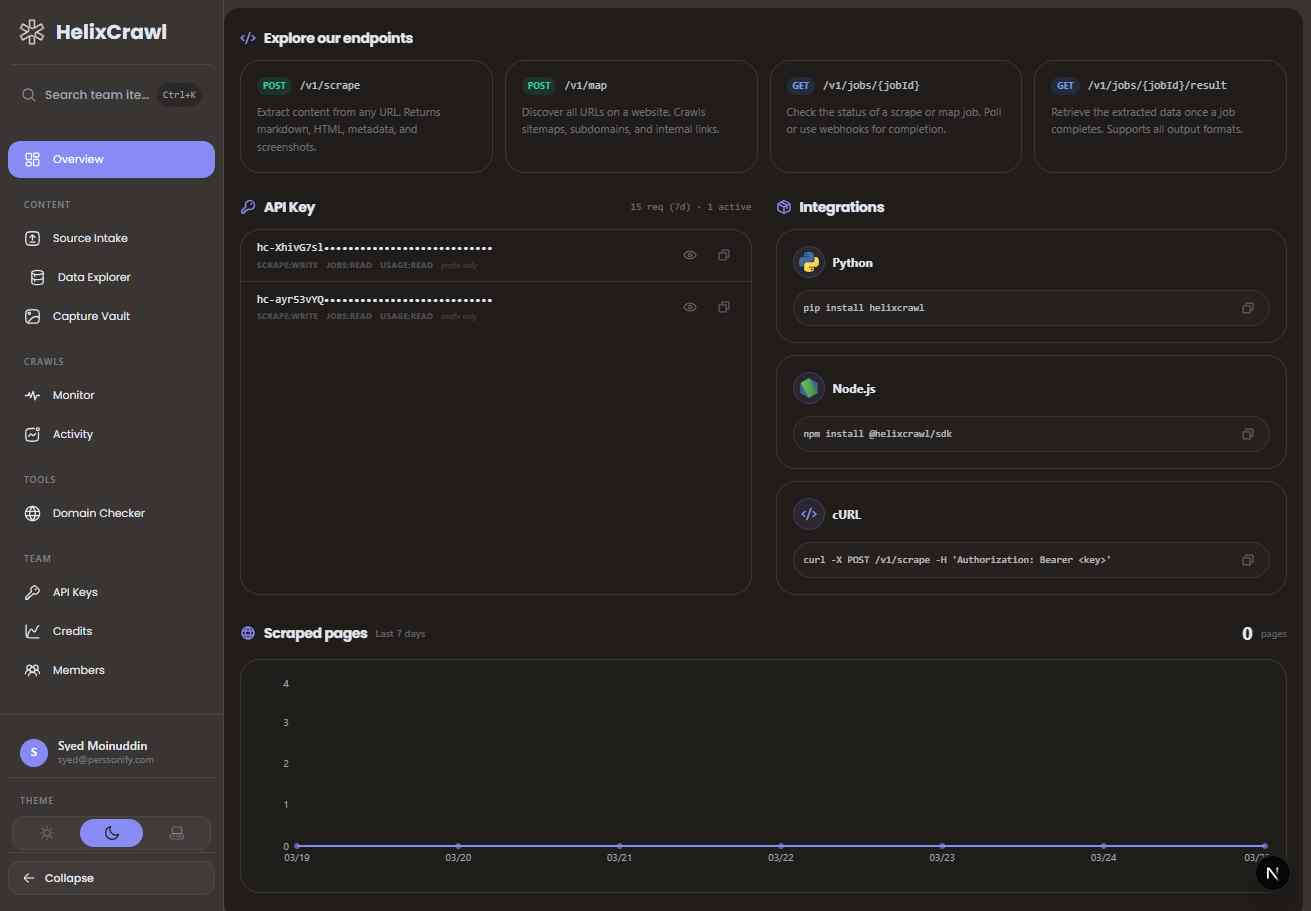
Extract Data at Scale
Our platform provides the infrastructure and tools you need to crawl any website reliably. Focus on building your product — we handle the complexity.
Globally Distributed
Crawl from multiple regions worldwide. Our proxy network spans 195+ countries, ensuring you always get local results with low latency.
Scalable Compute
Handle traffic spikes and complex workloads effortlessly. Spin up hundreds of concurrent crawls without managing any infrastructure.
Structured Output
Get clean Markdown, JSON, or raw HTML — perfectly formatted and ready for your LLM, database, or analytics pipeline.
Anti-Bot Bypass
Cloudflare, Akamai, reCAPTCHA — we handle them all automatically so your crawls never get blocked or throttled.
Every unstructured page is a missed insight. Every blocked request costs you momentum. Our infrastructure extracts instantly, bypasses defenses seamlessly, delivers clean data at scale, and keeps your pipelines running around the clock — so you ship faster while others are still parsing HTML.
Everything you need to crawl the web
Capabilities
Key Features
Discover the powerful capabilities that make Helix Crawl the go-to infrastructure for web data extraction. Built for reliability, speed, and scale.
Get startedAnti-Bot Bypass
Automatically defeats Cloudflare, Akamai, reCAPTCHA, and other protections so your crawls never get blocked.
Headless Rendering
Full JavaScript execution with headless browsers. Crawl SPAs, dynamic pages, and infinite scroll content effortlessly.
Structured Output
Get clean Markdown, JSON, or raw HTML — perfectly formatted and ready for your LLM, database, or analytics pipeline.
API Plans
Scale your crawling with the right plan.
Choose from our plans designed to grow with you — from hobby projects to enterprise-grade data pipelines.
All plans include a free consultation and onboarding session.
Custom Solutions
Need a tailored approach?
Contact us for custom crawling infrastructure, dedicated proxy pools, or on-premise deployment that aligns with your requirements.
Support
Ongoing optimization
We continuously monitor platform health and optimize for reliability. Need help? Contact us
We've got answers
Everything you need to know about Helix Crawl. Can't find what you're looking for? Reach out to our support team.